CS106L_Lecture3-Types and Advanced Streams
cin 的读取
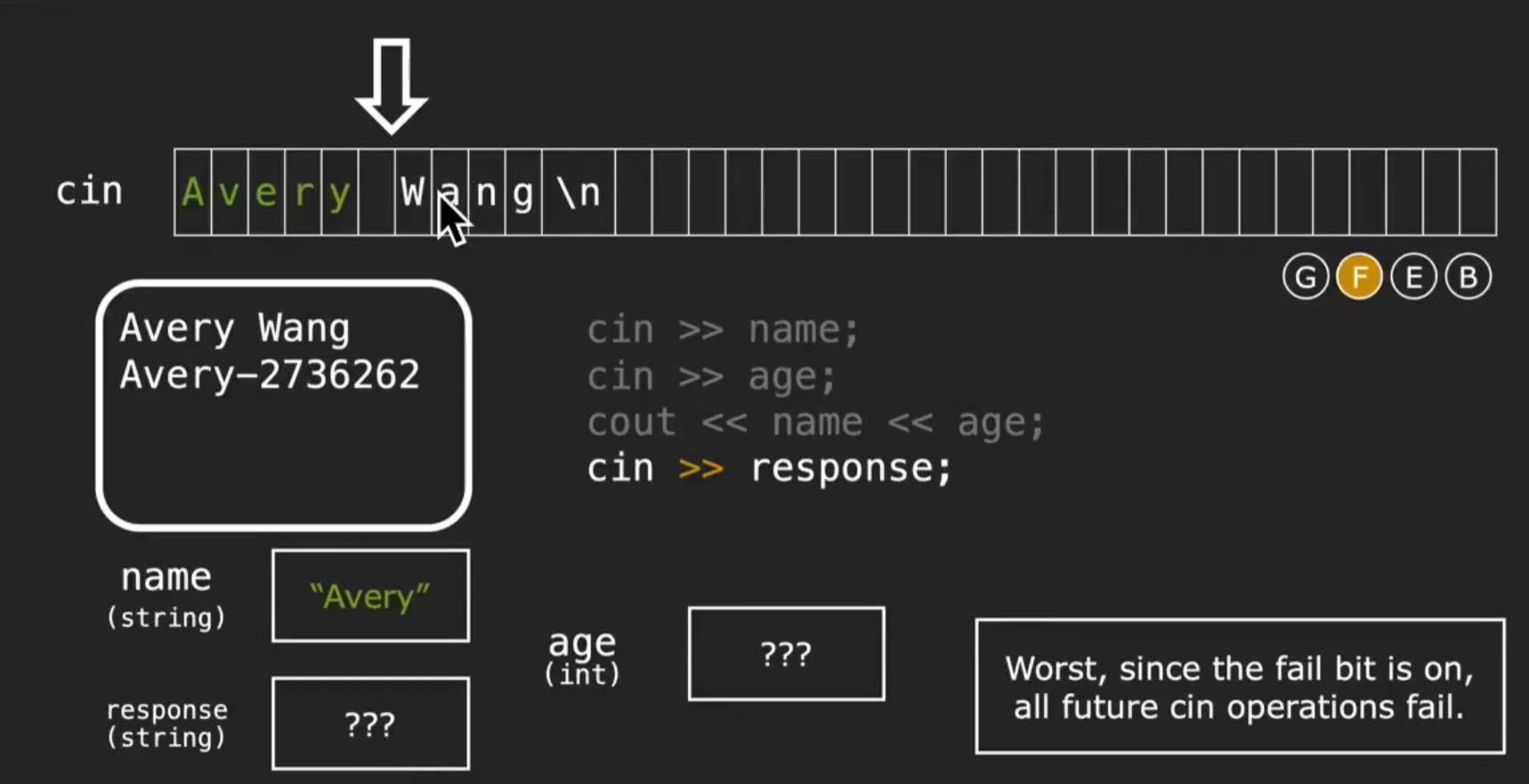
我们可以看到,当我们输入 Avery Wang 时,
在 cin 的缓冲区里,只有 Avery 被读走了,后面还剩 Wang\n
而下一个将要被读取的位置在 W 这里
为什么 cin >> name; 只读取出 “Avery”?
因为对于字符串 name 来说,>> 默认是 按空白分隔读取 的
也就是说它会:
跳过前导空白
一直读,直到遇到空格、换行、tab为止
为什么 cin >> age; 会失败
在输出结果中,显示的 age 是 0 ,
这是因为 age 是 int,
cin 期待读取到一个整数,
而缓冲区里下一个有效字符是 W ,而不是数字
于是:
cin 无法将 W 解析成 int
从而本次读取失败
fail bit 被设置为 1
所以我们可以看到右边的状态位中,F被点亮了
The worst
一旦 fail bit 被置上,后续所有的 cin 读取都会直接失败!
第一版修复
1 | int getInteger(const string& prompt) { |
这里是先把输入读成字符串,再自己解析。
但是仍然存在问题
问题 A
cin >> token 还是只读取一个token
例如我们输入
1 | 20 lol |
那cin >> token 只会读到
1 | token = "20" |
后面的 lol 还留在原始输入缓冲区里
问题 B
1 | return getInteger(prompt); |
这个写法叫 递归重试
它的问题是:
- 输入错误很多次,会一层一层递归下去
- 虽然程序里未必立刻出事,但设计上不优雅
- 重试逻辑本来就更适合 while (true) 循环
终版修复
1 | int getInteger(const string& prompt) { |
这里先用 getline 把整行读出来,
再把这一整行去解析
这里 getline(cin, line) 的意思是: 从 cin 这个输入流里,读取一整行,存到 line 里
函数原型是 getline(输入流, 字符串变量);
它还可以从字符串流读
1 | istringstream iss("hello\nworld"); |
cin 与 getline 的区别
cin >> line
读一个 token,遇到空白就停
getline(cin, line)
读一整行,默认遇到换行符 \n 才停,并且会把这个换行符消费掉,但不会放进结果字符串里。
混用 >> 与 getline 出现的 bug
1 | istringstream iss("16.9 Ounces\n Pack of 12"); |
我们会发现:
amount 读出来是对的,但 unit 却不是你以为的 “Ounces” 或 “ Ounces”,而是先变成了空字符串
这是因为 >> 和 getline 对“分隔符/空白”的处理方式不同
iss >> amount 做了什么
假设流里一开始是
1 | 16.9 Ounces |
执行
1 | iss >> amount |
amount = 16.9
读取位置停在 16.9 后面的那个空格前后附近 的关键位置上
更准确地说,>> 在读 double 时,会把能构成 double 的部分读完,然后停下来,后面的空格/换行还在流里等待后续处理。
马上 getline(iss, unit) 会发生什么
getline 的规则是:
从当前位置开始,一直读到换行符 \n 为止。
它不会像 >> 一样先主动跳过前导空白。这一点特别重要。
所以如果当前位置前面正好残留了一个空格,或者更常见的是残留了一个换行符,那么 getline 可能直接读到“空内容”
最常见的坑
虽然说在CS106L中用的是 istirngstream, 但最常见的坑应该是在 cin 上,原因和 iss 的情况一样
重点1: getline 不会自动跳过前导空白
会先跳过前导空白
getline
不会跳过,它从当前位置直接开始读
所以只要你前面用 >> 留下了换行符,后面紧接一个 getline,就特别容易出问题
修复方法
1 | iss >> amount; |
这里加上 iss.ignore(), 再 getline 就可以正常读到”Ounces”
ignore() 的作用
可以把它理解成:
手动丢掉流里当前那个你不想要的字符
在这个例子里,就是把前面 >> 留下的那个分隔字符先扔掉,然后再让 getline 从真正想读的位置开始读
一般情况,ignore()指忽略接下来的1个字符
如果是带参数
1 | ignore(n, '\n') |
表示 最多忽略 n 个字符,遇到分隔符 \n 时把该分隔符丢掉后停止
size_t
一个 warning 例子
1 | string str = "Hello World!"; |
很多编译器会发出警告:signed / unsigned comparison
为什么会警告
因为:
- i 是 int,是 signed(有符号)
- str.size()返回的通常是 size_t,是 unsigned(无符号)
所以这句
1 | i < str.size() |
本质上是在比较:
有符号整数 VS 无符号整数
size_t 是什么
我们可以简单理解成:专门用开表示“大小、长度、索引”这类永远不会是负数的整数类型
比如:
- 字符串长度
- 容器大小
- 数组下标
优化写法
所以更好的写法是:
1 | for (size_t i = 0; i < str.size(); ++i) { |
size_t 带来的 bug
来看这段代码:
1 | string chopBothEnds(const string& str) { |
这段代码看上去像是在“去掉首尾字符”
但是当 str 很短的时候
比如 str = “”
那么 str.size() == 0
而 size_t 是无符号数
所以 0 - 1 不会变成 -1,而是会发生下溢,变成一个非常大的数
这就回让循环条件变得很危险
type alias
type alias 叫做 类型别名
例如:
1 | using map_iterator = std::unordered_map<forward_list<Student>, |
这表示:
给这个超长的类型名起一个新名字:map_iterator
然后我们就可以写:
1 | map_iterator begin = studentMap.cbegin(); |
它的作用就是 简化
当类型特别长、特别丑、反复出现时,起别名能让代码更可读
auto
如果类型不重要,或者编译器很容易推断出来,就可以用 auto
例如:
1 | auto begin = studentMap.cbegin(); |
这里我们根本不需要死记那个迭代器的完整类型
我们只用关心:它是个能用的 iterator
那交给编译器推断就行
注意事项
1 | auto name = "Avery"; |
这个类型不是 string,而是更接近 C 风格字符串
如果真要写 string,要写:
1 | auto betterName1 = string{"Avery"}; |
auto discards const and references!!!
auto 会丢掉引用和顶层 const
例如:
1 | const string& s = someString; |
那 x 往往不是 const string&,而是一个新的 string 副本
也就是说:
原来是引用
结果 auto 一推断,变成值拷贝了
如果想保留引用属性,要显式写:
1 | auto& x = s; |
如果是
1 | const auto& x = s; |
那么我们不能通过 x 修改 s,只能用 x 引用 s
也就是只读引用
这是遍历大对象并只读时最推荐的写法
所以以后看到 auto,我们要想一下我们要的是值还是引用
pair、tuple、struct
pair
pair 表示一对值
1 | auto prices = make_pair(3.4, 5); |
这里 prices 的类型是:
1 | pair<double, int> |
访问方式:
1 | prices.first |
tuple
tuple 可以表示多个值
1 | auto values = make_tuple(3, 4, "hi"); |
访问方式
1 | get<0>(values) |
structured binding 结构化绑定
这是 modern C++ 里特别好用的语法
例如:
1 | auto [a, b] = prices; |
意思是把 pair 里的两个值直接拆出来,分别赋值给 a 和 b
再比如:
1 | const auto& [x, y, z] = values; |
这里就是把 tuple 里的每一项分别赋值给 x,y,z
struct
如果这些值本来就是“同一个对象的多个属性”,那通常 struct 比 pair/tuple 更清晰
1 | struct Discount { |
然后创建对象;
1 | auto coupon1 = Discount{0.9, 30, "New Years"}; |
reference 引用
看这个例子:
1 | string tea = "Ito-En"; |
这里有三种东西:
tea:原对象
copy:拷贝
ref:引用,给 tea 起了个别名
拷贝和引用的区别
拷贝:copy 是独立对象
改变 copy 并不会对 tea 造成影响
引用:ref 就是 tea 的另一个名字
改变 ref,就是在改变 tea
引用不能改绑
1 | ref = copy |
这不是让 ref 改为引用 copy
而是 把 copy 的内容赋值给 ref 绑定对对象 tea
也就是说,引用一旦绑定,通常就不能重新指向别的对象了
dangling reference 悬空引用
never return references to local variables!
永远不要返回对局部变量的引用!
1 | char& firstCharBad(string& s) { |
这里返回的是 local[0] 的引用
但问题是:local 是局部变量
函数一结束 local就销毁了
那么返回出去的引用,就指向了一个不存在的对象
这就是悬空引用
这个引用看起来还能用,实际上已经指向无效内存了。
属于未定义行为
正确写法:
1 | char& firstCharGood(string& s) { |
这里返回的是调用者传进来的字符串 s 里的字符引用
只要 s 活着,这个引用就是有效的
uniform initialization 统一初始化
统一初始化也叫花括号初始化
1 | vector<int> vec{3, 1, 4, 1, 5, 9}; |
还有
1 | Course now{ |
这是在用一种统一、现代的方式初始化各种对象
它在 modern C++ 里很常见,尤其配合:
struct
vector
返回值构造